Introducing FlaSH, Part 1: Meet the Team

Delphi publishes millions of public-health-related data points per day, such as the total number of daily COVID-19 cases, hospitalizations, and deaths per county and state in the United States (US). This data helps public health practitioners, data professionals, and members of the public make important, informed decisions relating to health and well-being.
Yet, as data volumes continue to grow quickly (Delphi’s data volume expanded 1000x in just 3 years), it is infeasible for data reviewers to inspect every one of these data points for subtle changes in
- quality (like those resulting from data delays) or
- disease dynamics (like an outbreak).
These issues, if undetected, can have critical downstream ramifications for data users (as shown by the example in Fig 1).
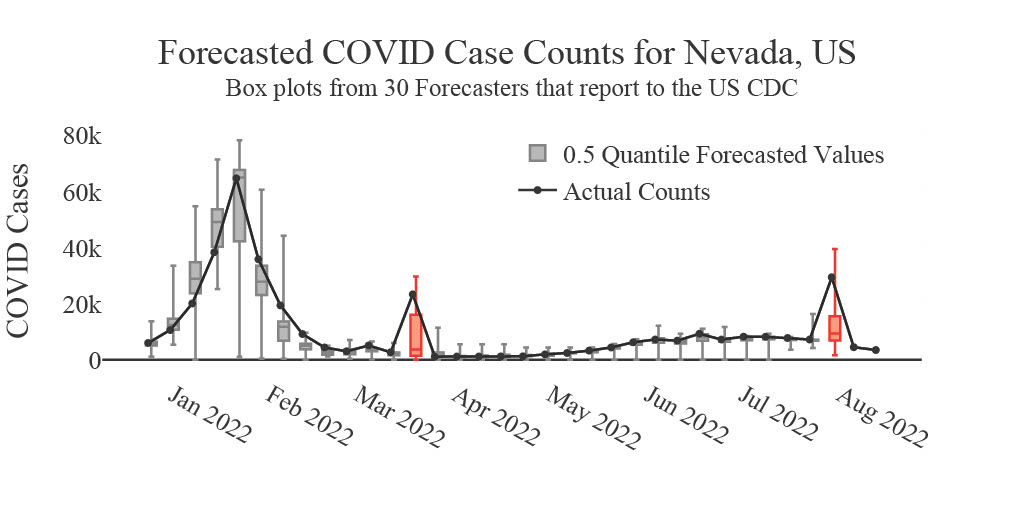
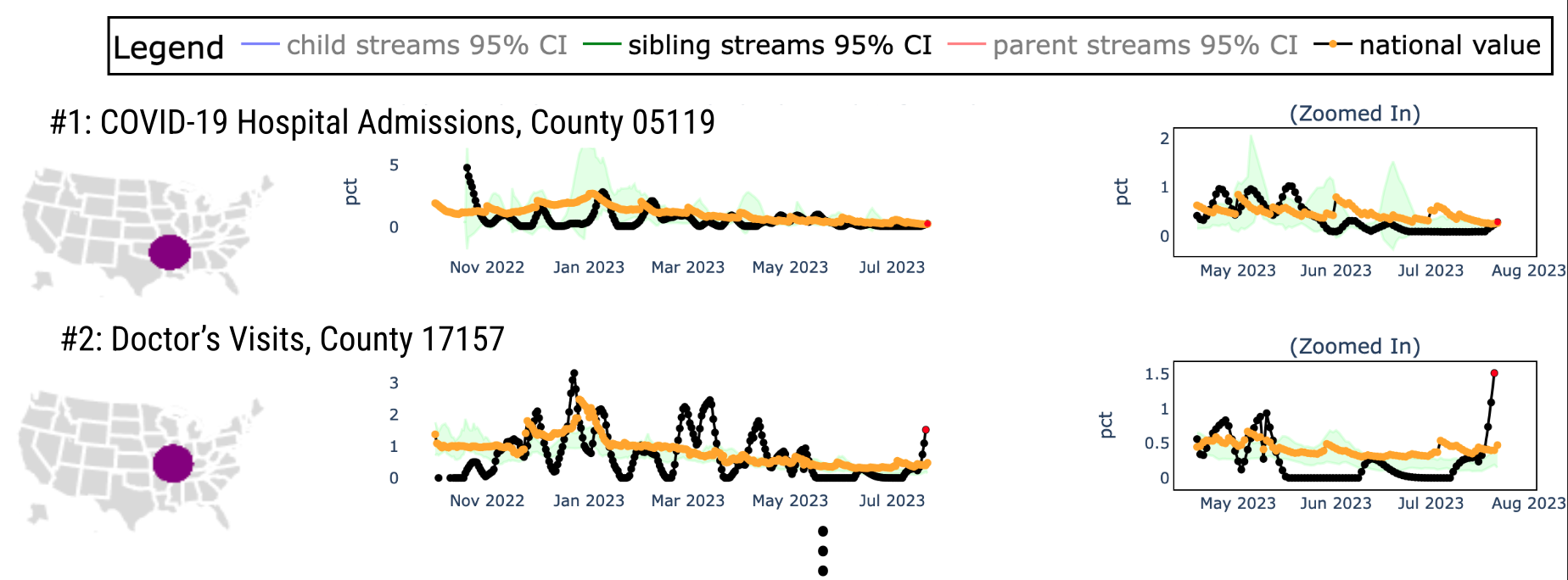
We care about finding data issues like these so that we can alert downstream data users accordingly. That is why our goal in the FlaSH team (Flagging Anomalies in Streams related to public Health) is to quickly identify data points that warrant human inspection and create tools to support data review. Towards this goal, our team of researchers, engineers, and data reviewers iterate on our deployed interdisciplinary approach. We will cover the different methods and perspectives of the FlaSH project, starting with the visualization and user experience perspectives.
Visualization and User Experience
Perspectives from our expert data reviewer, who has been working with this system for over a year – Tina Townes.
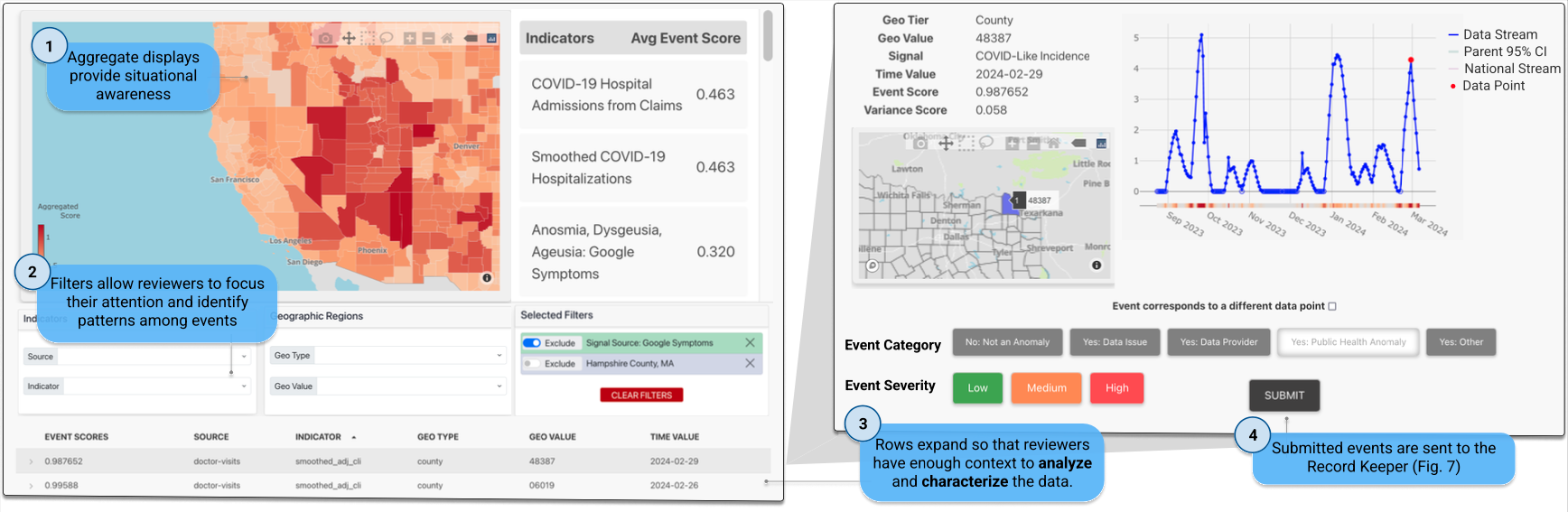
In its initial stages, the FlaSH dashboard (Fig 2b) only enabled me to assess potential anomalies by viewing graphs, line-by-line for each location of the numerous signals that have flagged anomalies, as generated by the FlaSH program. This was a particularly daunting task as daily FlaSH outputs generated and continue to produce a large number of reports in the form of compressed lines that required clicking on to expand and reveal more details. Without the new dashboard’s features, I was spending a significant amount of time scrolling through the daily list of anomaly reports and manually sorting what I wanted to review by clicking on and expanding only certain report lines and leaving them expanded until I was done with my selection process and ready to review the expanded lines. I would also often make notes and document interesting patterns in anomalies in a separate notepad, decreasing the efficiency and speed of my review process. My attention became divided as I was parsing though the daily anomaly list to search for reports in certain geographies (I knew I wanted to examine these due to prior report patterns), while simultaneously trying to focus on assessing new anomalies.
With the old dashboard setup, it was not easy for me to review the lines of daily anomaly reports because I couldn’t efficiently filter various incoming anomalies when I needed to examine specific geographic areas or signals. For example, one particular week I was seeing a lot of anomaly reports in a county in Puerto Rico Monday through Wednesday. By Thursday of that week I wanted to, upon logging into the platform, immediately proceed to filter the daily anomaly reports to look specifically at that Puerto Rican county right away, but had no way of filtering by geography with the old dashboard. The updated dashboard now has a menu that lets me efficiently select to filter lines not only by the geographic regions, but also by various indicators as well. This new setup speeds up my daily review process as it lets me quickly focus on specific geographies and finish reviewing those so that I can move on and focus on examining other anomaly reports in different geographies.
Now, in its current iteration (Fig 2a), the FlaSH dashboard lets me easily filter daily anomaly results by various variables including geos and signal types, and also view a national map offering a quick glimpse of locations of high FlaSH scores. Furthermore, the updated FlasH dashboard now enables me to take detailed notes on particularly interesting anomalies, trends and other issues of importance, and maintain these notes in an organized, searchable fashion within the platform.
Finally, now with the dashboard’s repositioned filtering menu, the page layout becomes an even more familiar environment. The menu echoes the user-friendly layouts of popular retail and informational sites, making navigation much more intuitive and smoother, thus allowing me to work through various options more quickly.
These new dashboard features allow me to devote more of my time and efforts to assessing anomalies of interest and focus on geographies with high concentrations of problematic data or noteworthy trends.
Additional Information
For more information, please check out our demo video, open-source methods (1) (2), and publications (1) (2).
Members: Ananya Joshi, Nolan Gormley, Richa Gadgil, Tina Townes, Catalina Vajiac (part time)
Former Members: Luke Neurieter, Katie Mazaitis
Advisors: Peter Jhon, Roni Rosenfeld, Bryan Wilder
Revised July 12th 2024


